En una entrada anterior os hablé de dwm y las bondades de este pequeño gestor de ventanas. También mencioné por encima cómo parchearlo para adaptarlo un poco mejor a nuestras preferencias. Hoy voy a compartir con vosotros algunos de los parches que utilizo en mi configuración, son pocos y sencillos:
1. Pertag
Fundamental. Este parche permite tener un layout distinto en cada tag. Si recordáis cómo funciona dwm, cada ventana puede asociarse a uno o varios tags (algo así como escritorios virtuales) entre los cuales nos podemos mover mediante atajos de teclado. Además, dwm incluye tres layouts distintos: floating (las clásicas ventanas flotantes), tiling (las ventanas se organizan automáticamente para ocupar todo el espacio de pantalla disponible) y monocle (una ventana maximizada tiene el foco y oculta el resto de ventanas bajo el mismo tag, que son accesibles mediante atajos de teclado). Por defecto, dwm aplica el mismo layout en todos los tags; con este parche podemos establecer un layout independiente para cada tag (por ejemplo, si utilizas un tag dedicado para edición fotográfica probablemente prefieras tener un layout “monocle” antes que “tiling”; en un tag para terminales es más útil el layout “tiling”, etc).
2. Focusonnetactive
De nuevo, un imprescindible. Desde el punto de vista técnico: por defecto dwm establece un bit de urgencia (urgency bit) en
respuesta a un mensaje de tipo _NET_ACTIVE_WINDOW por parte de un cliente. Con este parche conseguimos que en lugar de establecer el bit de urgencia, se active la ventana en cuestión. En lenguaje terrenal, esto quiere decir que en lugar de mostrarse una alerta visual en el tag que contiene la ventana (normalmente cambia de color), dwm directamente cambiará el foco y activará esa ventana. Por ejemplo, pongamos que estoy navegando por mi feed con newsboat y presiono “o” para abrir el artículo en el navegador. Sin el parche lo que ocurriría es que mi tag del navegador cambiaría de color, pero yo seguiría viendo mi terminal con newsbeuter. Con el parche, dwm directamente me cambia a la ventana del navegador en cuanto presiono “o”. Tal que así:
3. Colorbar
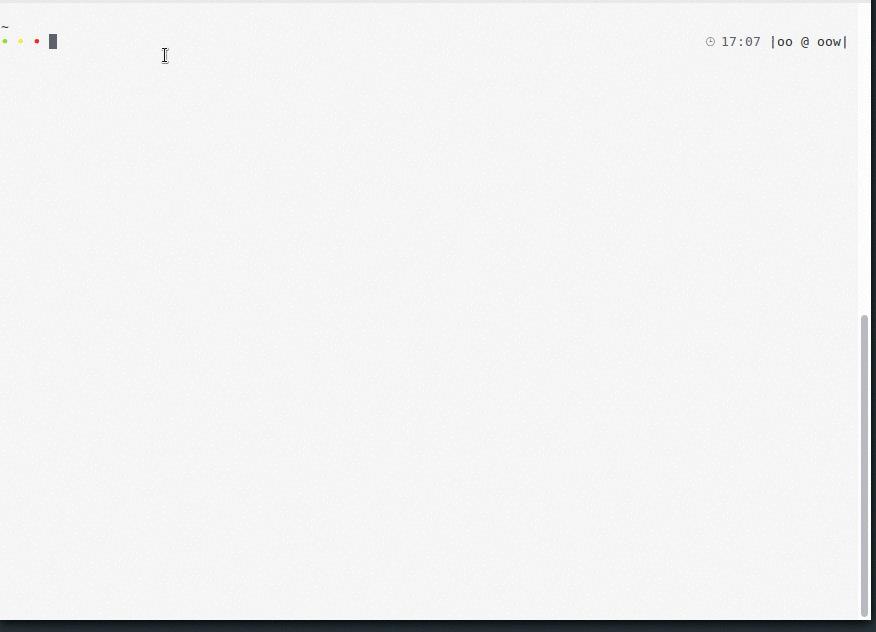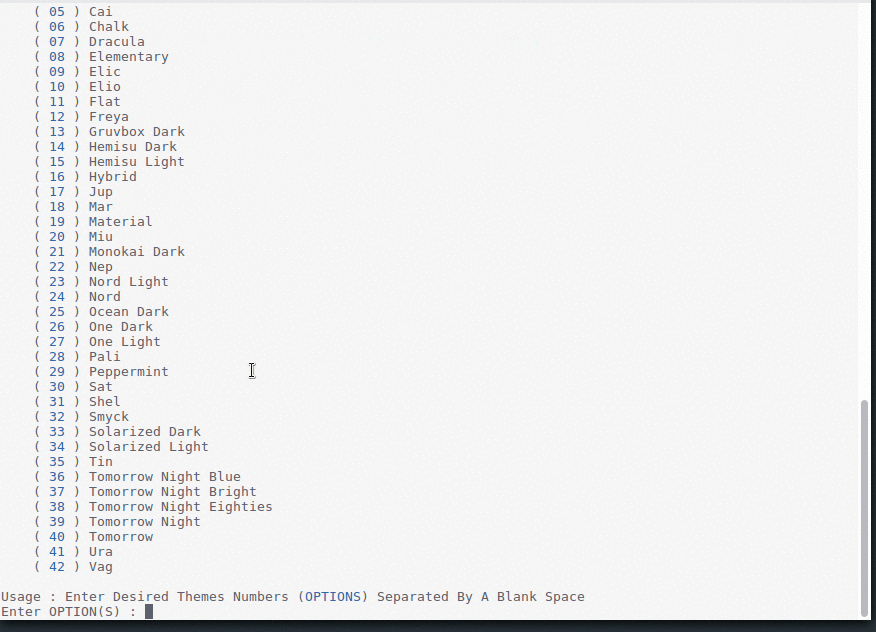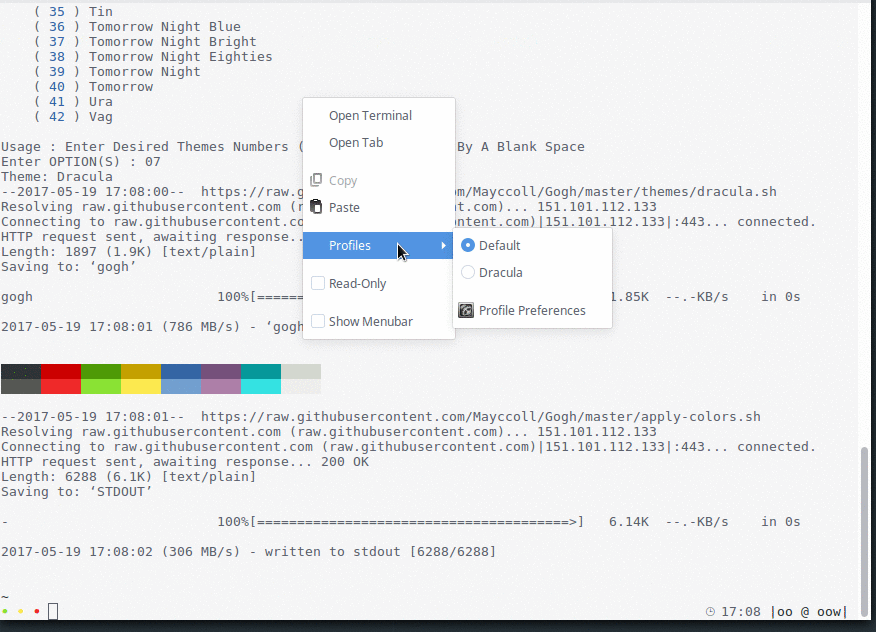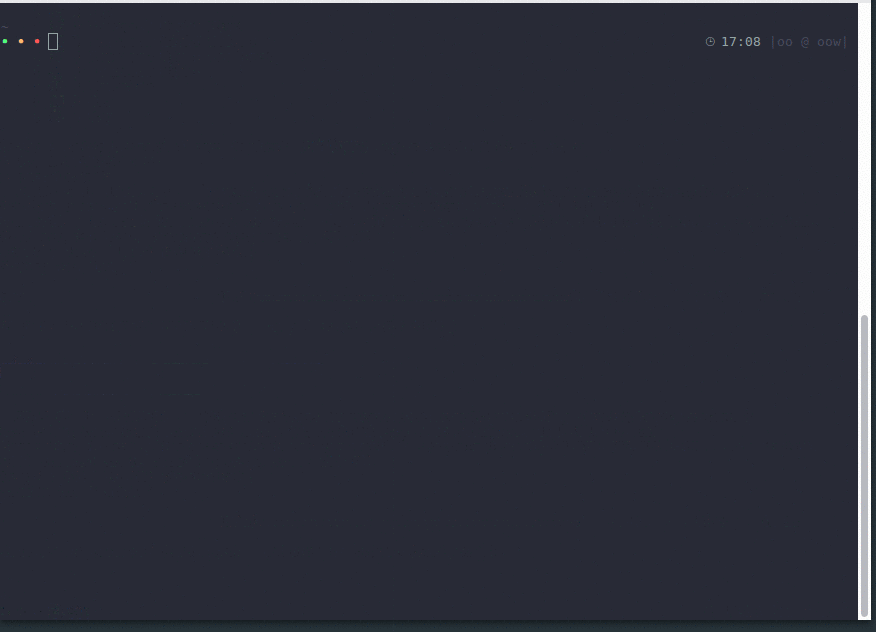
Tanto este parche como el próximo son algo más prescindibles y responden fundamentalmente a criterios estéticos. Lo que hace colorbar es permitir establecer colores en el tagbar (la porción de la barra a la izquierda donde aparecen los tags), infobar (la parte central, que contiene el nombre de la ventana) y statusbar (parte derecha, donde podemos mostrar lo que queramos via xsetroot) de manera independiente. Con un par de imágenes se entiende mejor:
a) Sin colorbar

(El tagbar y infobar tienen el mismo color de resaltado; el color por defecto del statusbar es el mismo que el del tagbar no seleccionado).
b) Con colorbar

Este parche modifica el config.h, así que mucho cuidado al introducirlo, recordad hacer copia de vuestro config.h antes.
Para definir los colores:
static const char *colors[][3] = {
/* fg bg border */
[SchemeNorm] = { col_gray, col_bar, col_gray },
[SchemeSel] = { col_white, col_gray, col_blue4 },
[SchemeStatus] = { col_white, col_bar, "#000000" }, // Statusbar right {text,background,not used but cannot be empty}
[SchemeTagsSel] = { col_blue4, col_bar, "#000000" }, // Tagbar left selected {text,background,not used but cannot be empty}
[SchemeTagsNorm] = { col_gray4, col_bar, "#000000" }, // Tagbar left unselected {text,background,not used but cannot be empty}
[SchemeInfoSel] = { col_blue4, col_bar3, "#000000" }, // infobar middle selected {text,background,not used but cannot be empty}
[SchemeInfoNorm] = { col_bar, col_bar, "#000000" }, // infobar middle unselected {text,background,not used but cannot be empty}
};
4. Uselessgap
Como su propio nombre indica, este parche permite introducir “useless gaps” (“espacios inútiles”) entre ventanas. Aunque también hace otra cosa (que es la razón por la que lo utilizo), que es impedir que dwm dibuje un marco coloreado alrededor de la ventana cuando está maximizada. Esto es muy útil en modo tiling para distinguir más fácilmente qué ventana tiene el foco, pero cuando solo hay una ventana maximizada no tiene mucho sentido.
La configuración es muy sencilla:
static const unsigned int gappx = 0; /* gap pixel between windows */
Si configuráis el tamaño de gap en 0 no habrá espacio entre las ventanas y os habréis librado del molesto borde.
Para terminar, os dejo aquí mi config.h actualizado, por si os animáis a probar dwm:
/* See LICENSE file for copyright and license details. */
/* appearance */
static const unsigned int borderpx = 2; /* border pixel of windows */
static const unsigned int snap = 32; /* snap pixel */
static const int showbar = 1; /* 0 means no bar */
static const int topbar = 1; /* 0 means bottom bar */
static const char *fonts[] = { "Cantarell:size=13", "Font Awesome:size=12" };
static const char dmenufont[] = "JetBrains Mono Medium:size=12";
static const char col_bar[] = "#2F343F"; /* Dark grey matching arc theme */
static const char col_bar_rev[] = "#414857"; /* Slightly lighter grey for infobar middle bg */
static const char col_bar_name[] = "#7C818C"; /* Grey for window names */
static const char col_bar_name2[] = "#ACB6C3"; /* Grey for window names */
static const char col_blue[] = "#5294E2"; /* Arc blue */
static const char col_purple[] = "#DC8ADD";
static const char col_white[] = "#F6F5F4";
static const char col_red[] = "#CC575D";
static const char col_yellow[] = "#B58900";
static const char col_gray[] = "#5E5C64";
static const char col_gray2[] = "#77767B";
static const char col_gray3[] = "#9A9996";
static const char col_gray4[] = "#C0BFBC";
static const char col_gray5[] = "#DEDDDA";
static const char *colors[][3] = {
/* fg bg border */
[SchemeNorm] = { col_gray, col_bar, col_bar_name },
[SchemeSel] = { col_white, col_gray, col_blue },
[SchemeStatus] = { col_white, col_bar, "#000000" }, // Statusbar right {text,background,not used but cannot be empty}
[SchemeTagsSel] = { col_blue, col_bar, "#000000" }, // Tagbar left selected {text,background,not used but cannot be empty}
[SchemeTagsNorm] = { col_bar_name, col_bar, "#000000" }, // Tagbar left unselected {text,background,not used but cannot be empty}
[SchemeInfoSel] = { col_bar_name2, col_bar_rev, "#000000" }, // infobar middle selected {text,background,not used but cannot be empty}
[SchemeInfoNorm] = { col_bar, col_bar, "#000000" }, // infobar middle unselected {text,background,not used but cannot be empty}
};
/* Gaps */
static const unsigned int gappx = 8; /* gap pixel between windows */
/* tagging */
/* static const char *tags[] = { "1", "2", "3", "4", "5", "6", "7", "8", "9" }; */
static const char *tags[] = { "", "", "", "", "", "", "", "", "" };
static const Rule rules[] = {
/* xprop(1):
* WM_CLASS(STRING) = instance, class
* WM_NAME(STRING) = title
*/
/* class instance title tags mask isfloating monitor */
{ "Gimp", NULL, NULL, 0, 1, -1 },
{ "Firefox", NULL, NULL, 1 << 1, 0, -1 },
{ "Keepassx", "^keepassx$", NULL, 0, 1, -1},
{ "Lxrandr", "^lxrandr", NULL, 0, 1, -1},
};
/* layout(s) */
static const float mfact = 0.50; /* factor of master area size [0.05..0.95] */
static const int nmaster = 1; /* number of clients in master area */
static const int resizehints = 0; /* 1 means respect size hints in tiled resizals; 0 avoids empty space at right side of terminals */
static const Layout layouts[] = {
/* symbol arrange function */
{ "", tile }, /* first entry is default */
{ "", NULL }, /* no layout function means floating behavior */
{ "[M]", monocle },
};
/* key definitions */
#define MODKEY Mod1Mask
#define TAGKEYS(KEY,TAG) \
{ MODKEY, KEY, view, {.ui = 1 << TAG} }, \
{ MODKEY|ControlMask, KEY, toggleview, {.ui = 1 << TAG} }, \
{ MODKEY|ShiftMask, KEY, tag, {.ui = 1 << TAG} }, \
{ MODKEY|ControlMask|ShiftMask, KEY, toggletag, {.ui = 1 << TAG} },
/* helper for spawning shell commands in the pre dwm-5.0 fashion */
#define SHCMD(cmd) { .v = (const char*[]){ "/bin/sh", "-c", cmd, NULL } }
#include <X11/XF86keysym.h>
/* commands */
static char dmenumon[2] = "0"; /* component of dmenucmd, manipulated in spawn() */
static const char *dmenucmd[] = { "dmenu_run", "-m", dmenumon, "-fn", dmenufont, "-nb", col_bar, "-nf", col_bar_name2, "-sb", col_yellow, "-sf", col_bar, NULL };
static const char *clipmenucmd[] = { "clipmenu", "-fn", dmenufont, "-nb", col_bar, "-nf", col_bar_name2, "-sb", col_purple, "-sf", col_bar, NULL };
static const char *termcmd[] = { "st", NULL };
static const char *roficmd[] = { "rofi", "-show", "window", NULL };
static const char *browsercmd[] = { "firefox", NULL };
static const char *officecmd[] = { "libreoffice", NULL };
static const char *editorcmd[] = { "mousepad", NULL };
static const char *filecmd[] = { "nemo","/home/user", NULL };
static const char *brightdowncmd[] = { "xbacklight","-dec", "5", NULL };
static const char *brightupcmd[] = { "xbacklight","-inc", "5", NULL };
static const char *mutecmd[] = { "volmute", NULL };
static const char *volupcmd[] = { "volup", NULL };
static const char *voldowncmd[] = { "voldown", NULL };
static const char *lockcmd[] = { "slock", NULL };
static const char *capturecmd[] = { "scrot","-s", NULL };
static Key keys[] = {
/* modifier key function argument */
{ MODKEY, XK_p, spawn, {.v = dmenucmd } },
{ MODKEY, XK_F2, spawn, {.v = dmenucmd } },
{ MODKEY, XK_o, spawn, {.v = clipmenucmd } },
{ MODKEY, XK_Return, spawn, {.v = termcmd } },
{ MODKEY, XK_b, togglebar, {0} },
{ MODKEY, XK_Right, focusstack, {.i = +1 } },
{ MODKEY, XK_Left, focusstack, {.i = -1 } },
{ MODKEY, XK_i, incnmaster, {.i = +1 } },
{ MODKEY, XK_d, incnmaster, {.i = -1 } },
{ MODKEY, XK_h, setmfact, {.f = -0.05} },
{ MODKEY, XK_l, setmfact, {.f = +0.05} },
{ MODKEY, XK_space, zoom, {0} },
{ MODKEY, XK_Tab, view, {0} },
{ MODKEY, XK_q, killclient, {0} },
{ MODKEY, XK_t, setlayout, {.v = &layouts[0]} },
{ MODKEY, XK_f, setlayout, {.v = &layouts[1]} },
{ MODKEY, XK_m, setlayout, {.v = &layouts[2]} },
{ MODKEY, XK_masculine, spawn, {.v = roficmd } },
{ MODKEY, XK_Escape, spawn, {.v = roficmd } },
{ MODKEY|ControlMask, XK_n, spawn, {.v = browsercmd } },
{ MODKEY|ControlMask, XK_o, spawn, {.v = officecmd } },
{ MODKEY|ControlMask, XK_e, spawn, {.v = editorcmd } },
{ MODKEY|ControlMask, XK_h, spawn, {.v = filecmd } },
{ 0, XF86XK_MonBrightnessDown, spawn, {.v = brightdowncmd } },
{ 0, XF86XK_MonBrightnessUp, spawn, {.v = brightupcmd } },
{ 0, XF86XK_AudioMute, spawn, {.v = mutecmd } },
{ 0, XF86XK_AudioRaiseVolume, spawn, {.v = volupcmd } },
{ 0, XF86XK_AudioLowerVolume, spawn, {.v = voldowncmd } },
{ 0, XK_Print, spawn, {.v = capturecmd } },
{ MODKEY|ControlMask, XK_l, spawn, {.v = lockcmd } },
{ MODKEY|ControlMask, XK_space, setlayout, {0} },
{ MODKEY|ShiftMask, XK_space, togglefloating, {0} },
{ MODKEY, XK_0, view, {.ui = ~0 } },
{ MODKEY|ShiftMask, XK_0, tag, {.ui = ~0 } },
{ MODKEY, XK_comma, focusmon, {.i = -1 } },
{ MODKEY, XK_period, focusmon, {.i = +1 } },
{ MODKEY|ShiftMask, XK_comma, tagmon, {.i = -1 } },
{ MODKEY|ShiftMask, XK_period, tagmon, {.i = +1 } },
TAGKEYS( XK_1, 0)
TAGKEYS( XK_2, 1)
TAGKEYS( XK_3, 2)
TAGKEYS( XK_4, 3)
TAGKEYS( XK_5, 4)
TAGKEYS( XK_6, 5)
TAGKEYS( XK_7, 6)
TAGKEYS( XK_8, 7)
TAGKEYS( XK_9, 8)
{ MODKEY|ShiftMask, XK_q, quit, {0} },
};
/* button definitions */
/* click can be ClkTagBar, ClkLtSymbol, ClkStatusText, ClkWinTitle, ClkClientWin, or ClkRootWin */
static Button buttons[] = {
/* click event mask button function argument */
{ ClkLtSymbol, 0, Button1, setlayout, {0} },
{ ClkLtSymbol, 0, Button3, setlayout, {.v = &layouts[2]} },
{ ClkWinTitle, 0, Button2, zoom, {0} },
{ ClkStatusText, 0, Button2, spawn, {.v = termcmd } },
{ ClkClientWin, MODKEY, Button1, movemouse, {0} },
{ ClkClientWin, MODKEY, Button2, togglefloating, {0} },
{ ClkClientWin, MODKEY, Button3, resizemouse, {0} },
{ ClkTagBar, 0, Button1, view, {0} },
{ ClkTagBar, 0, Button3, toggleview, {0} },
{ ClkTagBar, MODKEY, Button1, tag, {0} },
{ ClkTagBar, MODKEY, Button3, toggletag, {0} },
};
Happy hacking!!
















 EL pasado 12 de abril tuve el placer de participar en
EL pasado 12 de abril tuve el placer de participar en





















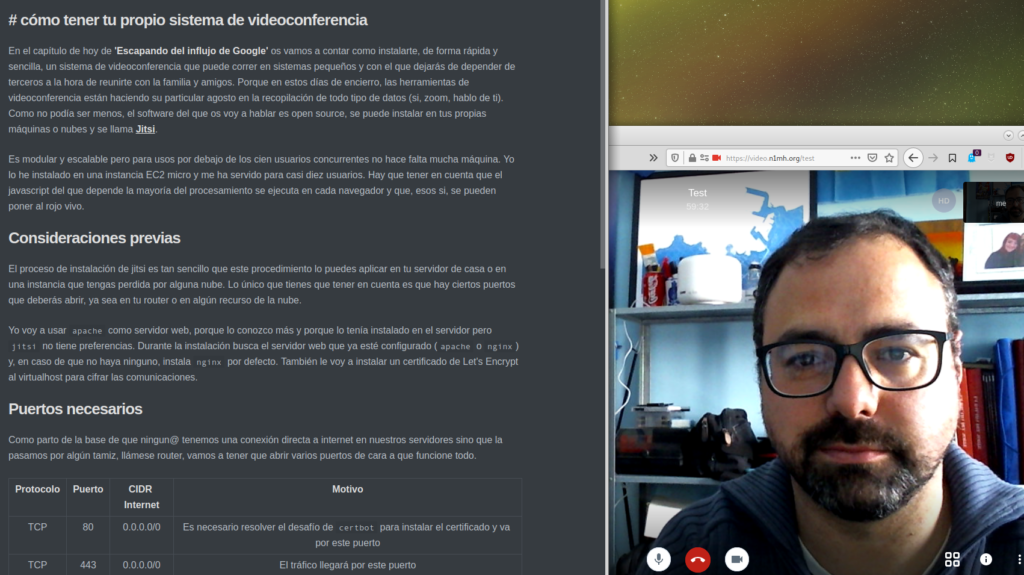 si, es mi cara de confinado…
si, es mi cara de confinado…
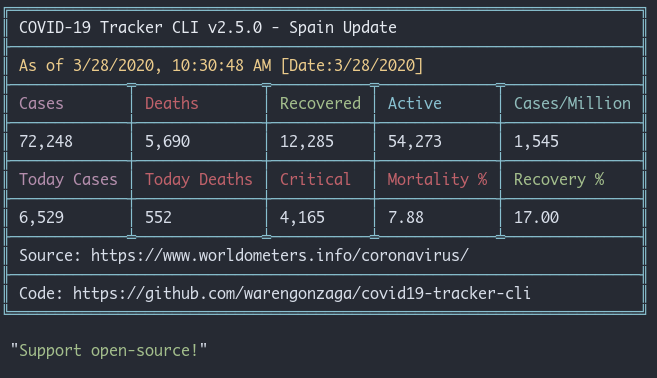







{kind=link}